【モナリザが歌いだす】写真を歌わせるAI「EMO」(エモ)とは?
アリババグループの研究者が画像1枚から写真を歌わせるAI、「EMO(エモ)」を開発しました。
EMOとは「Emote Portrait Alive(エモート・ポートレート・アライブ)」の略称です。直訳すると「生きた感情を表現するポートレート」となるでしょう。
EMOは「顔写真」と「音声」さえあれば、顔写真があたかも歌っているかのように動かすことができます。
今までの画像に歌わせるタイプのAIは、画像内の人物の口のみを動かしたり、顔が不自然に変形したりするものが多かったです。
しかし、このEMOでは口の動きや曲に合わせて、目や首、髪の毛などが自然に動きます。
百聞は一見に如かず、下の写真をクリックして動画をご覧ください!
私が特に好きな部分はレオナルド・ディカプリオがラップの曲を歌っているシーンでした。AIが生成する動画がここまでスムーズに歌っているとは信じられません。
モナリザが男性の曲を歌っているのもなかなかシュールです!
EMOが自然な顔の動きを再現できる仕組み
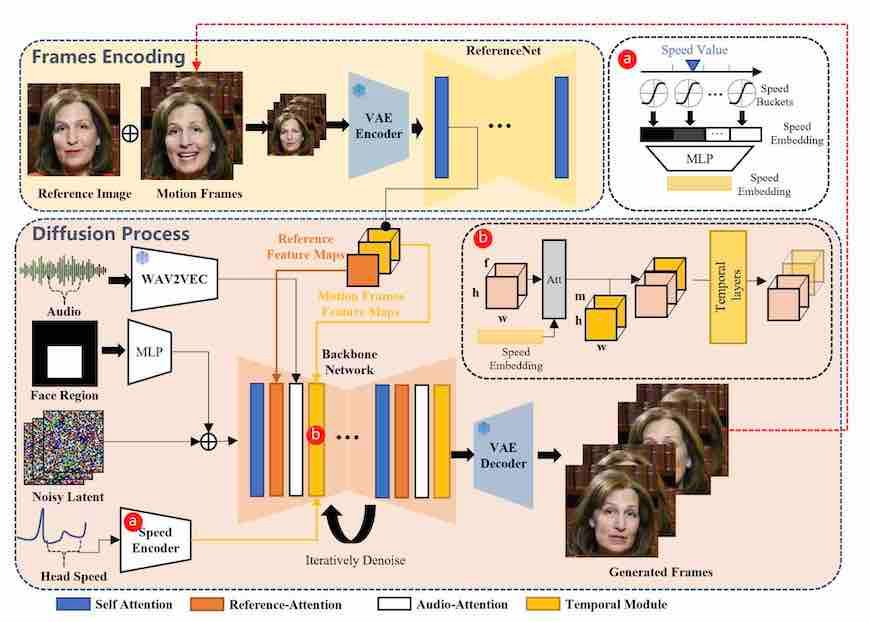
EMOがこんなにも自然な動きをする動画を生成できる仕組みは「フレーム・エンコーディング」と「ディフュージョン・プロセス」という2つの工程にあります。
1つ目のフレーム・エンコーディングでは、「1枚の写真から映像を生成する」技術、ReferenceNetと呼ばれるアリババが開発した手法が使われます。
この段階で、画像の中の顔を認識し、その顔がどんな動きをするかをAIが分析をします。そして、1枚の画像から動きのあるフレームを何百枚も生成するのです。
2つ目のディフュージョン・プロセスでは、実際に動画を音声と一緒に動かします。音楽を分析して、どのように口や首、目が動くかなどをAIが推測します。
そしてその分析をもとに画像をつなぎ合わせて、動画を生成していくのです。
また、このプロセスで動画内に含まれているノイズの除去なども行ったり、自然な早さに調節したりします。
(引用元:EMOテクニカルレポート)
↑EMOの仕組み。複雑ですが、大きく分けてしていることは上記で説明した「フレームエンコーディング・フレーム」と「ディフュージョン・プロセス」の2つのプロセスです。
驚くべき技術!しかし、ディープフェイクの懸念も高まる…
このEMO AIはまだ研究段階で、製品化はされていないようです。
しかし、多くの企業がAI開発が進めており、EMOのように写真1枚から人間の動きを再現できるサービスが出てくるのも時間の問題です。
もし、この写真を自然に動かせるAIが誰でも使えるようになれば、ディープフェイクがたくさん作られることでしょう。
今までにも岸田首相やバイデン大統領の映像や音声を真似したディープフェイクが作られ、SNS上で拡散されてきました。
このようなハイクオリティなAIが開発されるにつれて、ますます、ニセ情報や詐欺などに注意しなければなりません。
ただ、ディープフェイクという懸念が増す一方で新しい働き方も生まれるポジティブな考えもできると思います。
TikTokやYoutubeで自分好みのキャラクターとして活動し、インフルエンサーになることもできます。また、個人がドラマや映画を一人で作ったりするケースも増えていくことでしょう。
今まで出来なかったことが可能になることでビジネスチャンスが生まれます。そして、AIを使いこなすということ自体がスキルとして見なされる時代になっていくでしょう。
各国はAIに対して迅速に的確な法整備を進めていくことを求められる一方、個人はAIを使いこなすスキルを身につけ、AI時代のチャンスを掴んでいきたいですね。
参考文献
・EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak
・Alibaba presents EMO AI - All Demo Clips Upscaled to 4K
・Fake images made to show Trump with Black supporters highlight concerns around AI and elections