【LLM最新版】おすすめ日本語対応ローカルAIモデル8選!
GoogleやOpenAI、Metaといった大手テック企業のLLM(大規模言語モデル)がたびたび話題になっています。
その中でも、最近特に注目を浴びているのがローカルAIモデルの分野です。
パソコンやスマホ内でAIを動かすことができ、オフラインでもAIと会話することができます。
少しずつローカルLLMが開発されていますが、その中でも日本で使えるAIモデルはまだまだ少数派です。
しかし、日本企業も徐々に日本語特化のLLMをリリースし始めており、今後はより日本語に優れたAIが出てくることは間違いないでしょう。
この記事では、日本語に強みを持つおすすめのローカルLLMを紹介したいと思います!
日本語性能が高いローカルLLMまとめ
①「Command R+」:バツグンの安定性と高い日本語能力を持つAIモデル

(画像:CohereForAI/HuggingFaceから引用)
「Command R+」はCohereと呼ばれるアメリカのスタートアップによって2024年4月にリリースされたAIモデルです。
Cohereはこれまでオラクルやセールスフォース、エヌビディアといった企業から375億円以上もの資金調達を行っており、時価総額は2800億円を超えると言われています。
そんなCohereによって最先端のオープンソースAIは、1040億(104B)のパラメーター数を有している巨大なモデルです。
人によってはGPT-4やClaude 3、Gemini Proにも匹敵する性能を持つと感じる人いるとして、かなり話題になったAIモデルでした。
Command R+の強みは以下の点にあると言われています。
- RAG(検索拡張生成)が得意
- 英語、日本語、中国語、スペイン語、アラビア語他、10ヶ国の言語のレベルが高い
商用利用の可否について、CC-BY-NCライセンスに基づいて不可となっているようです。
下の画像では、「東京で観光するべき名所を教えて」という質問に対し、Command R+に日本語での回答してもらいました。
確かに、GPT-4ぐらいの性能はありそうな気がしてきます。日本語も間違ってませんし、観光名所についても詳しく説明してくれていますね!

(画像:lmsys Chatbot Arenaから引用)
②「Elyza-Llama2-7B-Instruct」: 松尾研初のスタートアップが開発したモデル

(画像:ELYZA, Inc noteより引用)
ELYZA, IncがLlama-2をベースとして作った商用利用可能な日本語LLMが「ELYZA-japanese-Llama-2-7b」です。
ELYZAは東京大学・松尾研究室から生まれたAIスタートアップで、AIモデルの開発を行っています。
今回、紹介するAIモデルは2023年8月にリリースされたモデルで、パラメータ数は70億(7B)になっており、性能はGPT-3.5に匹敵します。
このAIモデルを開発するのにあたって、人間からのフィードバックに基づいた強化学習がされた、日本語に優れたモデルをつくることができたようです。
7Bではありませんが、「ELYZA-japanese-Llama-2-70B」のデモ版も公式サイトで公開されており、ELYZAの日本語能力をテストすることができます。

(画像:ELYZA LLM公式デモサイトより引用)
上のような質問でも、ひっかけ問題にはひっかからないようです。
→elyza/ELYZA-japanese-Llama-2-7b-instruct
③「Llama-3-8B」:日本語にも対応予定のMeta社モデル

(画像:AI相談.com編集部がGPT4oより作成)
Llama-3-8BはMeta社(旧フェイスブック社)が開発したオープンソースのAIモデルです。Command R+と同様に2024年4月に公開されています。
パラメータ数は80億(8B)で、推論能力がかなり高く、ChatGPTやClaudeキラーになるかもしれないとウワサされているAIです。
また、商用利用も可能で、ユーザー数が7億人を超えない限りMeta社に利用料を支払う必要がないとのことです。
ここで注意したいのが、Llama3自体は日本語に特化したモデルではないことです。英語以外の言語には、正しい応答をしてくれることは少ないようです。
しかし、Llama 3のデータを使って作られたAIモデルは登場していきているので、日本語特化にファインチューニングされたLlama 3ベースのモデルを紹介します。
-「Suzume-llama-3-8B-japanese」:Llama 3をベースに作られた日本語特化型AIモデル

(画像:lightblue/HuggingFaceより引用)
ベンチマークも公表されており、サイバーエージェントや楽天のリリースしたAIモデルよりも優れた日本語能力になっているようです。
下の青いハイライトが「suzume」のベンチマークとなっています。オープンソースAIの中では、なかなかに高い日本語のベンチマークを記録しています。
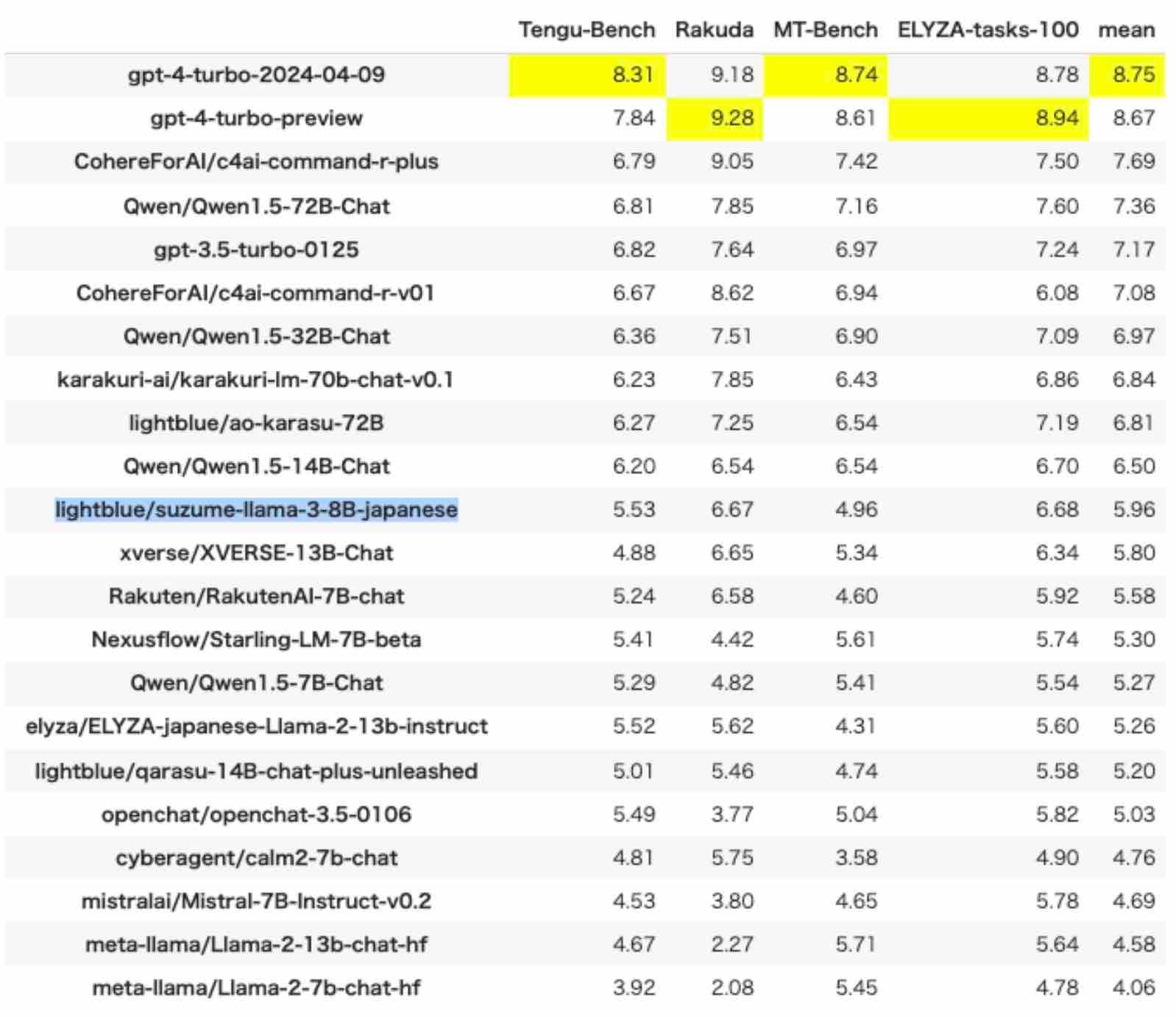
(画像:lightblue/HuggingFaceより引用)
→ lightblue/suzume-llama-3-8B-japanese
-「Llama-3-8b-Cosmopedia-japanese」:Llama 3をベースとした日本語対応モデル
こちらのAIモデルは、Cosmopediaという合成データを使ってLlama 3をファインチューニングしたLLMとなっています。
Cosmopediaのデータセット自体は、「Mistral8x7B」の高品質なアウトプットのみで構成されており余計なノイズを含まないことが利点であると説明されています。
ただ、Cosmopediaのデータセットは英語であることから日本語に翻訳してからデータを読み込ませているとのことです。
→ aixsatoshi/Llama-3-8b-Cosmopedia-japanese
④「Vecteus-v1」:伸びしろがすごい日本語特化モデル

(画像:Local-Novel-LLM-project/HuggingFaceより引用)
Vecteus-v1は「Mistral-7B-v0.1」をファインチューニングして作られた70億(7B)パラメータ数を持つAIです。
2024年5月にリリースされ、日本語能力に特化したAIとしてAIインフルエンサーからも紹介されています。
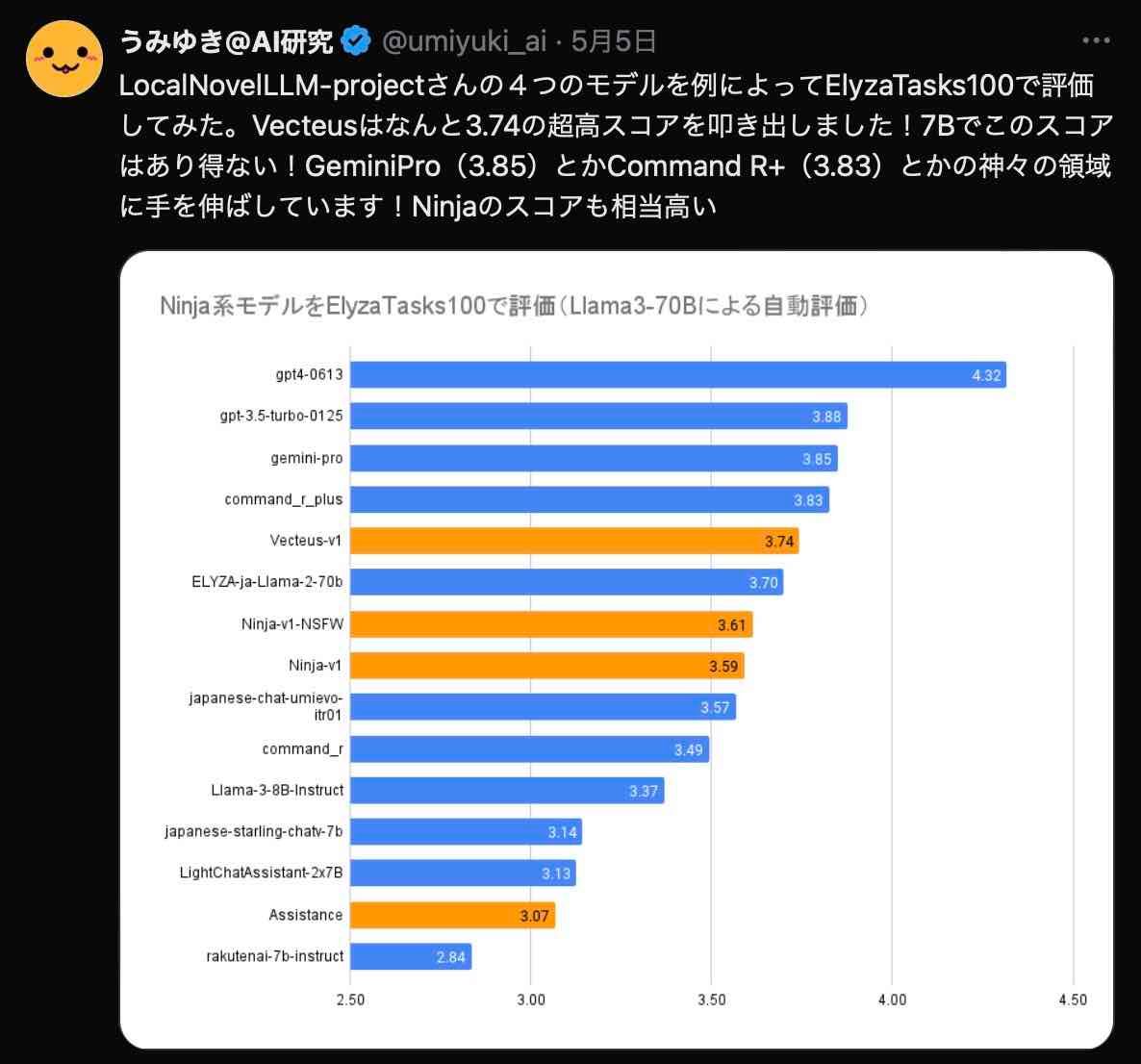
(画像:X うみゆき@AI研究 アカウントより)
LocalNovelLLM-projectさんはこれまでに、「Ninja」や「Assistance」と呼ばれるAIモデルを作っており、日本語に特化したモデルを作成してきたようです。
こちらのAIモデルもApache 2.0のライセンスが適用されており、商用利用も可能ですし、モデルの改変も可能となっています。
→ Local-Novel-LLM-project/Vecteus-v1
⑤「Ninja-v1」:ローカルAIハッカソンから生まれたモデル
(画像:Local-Novel-LLM-project/HuggingFaceより引用)
「Ninja-v1」も上記のVecteus-v1と同じ制作者がつくったAIモデルです。こちらのAIモデルも、Mistral AI社のAIモデル、「Mistral-7B-v0.1」をベースに作られました。
Ninjaは制作者がローカルAIハッカソンに参加したときに作ったモデルのようで、長いコンテクストのやり取りをした後でも、会話した内容を忘れないことが強みのようです。
パラメータ数は70億(7B)で商用利用も可能となっています。
→ Local-Novel-LLM-project/Ninja-v1
⑥「Command-R」:Cohereの原点であるAIモデル

(画像:Cohere公式サイトより引用)
Cohereが制作したCommand R+の前モデルのAIが「Command R」です。
2024年3月にリリースされたAIモデルで、パラメータ数は350億(35B)あります。
Command R+が出てきたことで、オリジナルのCommand Rの影が薄くなってはいますが、日本語能力はこちらも高いです。
Command R+はパラメータ数が1040億(104B)あるので、とても大きいモデルとなっていますが、それに比べるとCommand Rの方が使いやすいといえるでしょう。
商用利用は不可となっており、主に個人利用でのみ使用が許可されています。
「旅行客が日本で食べるべき物のリストを教えてください」という質問に対して、「寿司・ラーメン・天ぷら」という王道の回答を残すCommand Rです。
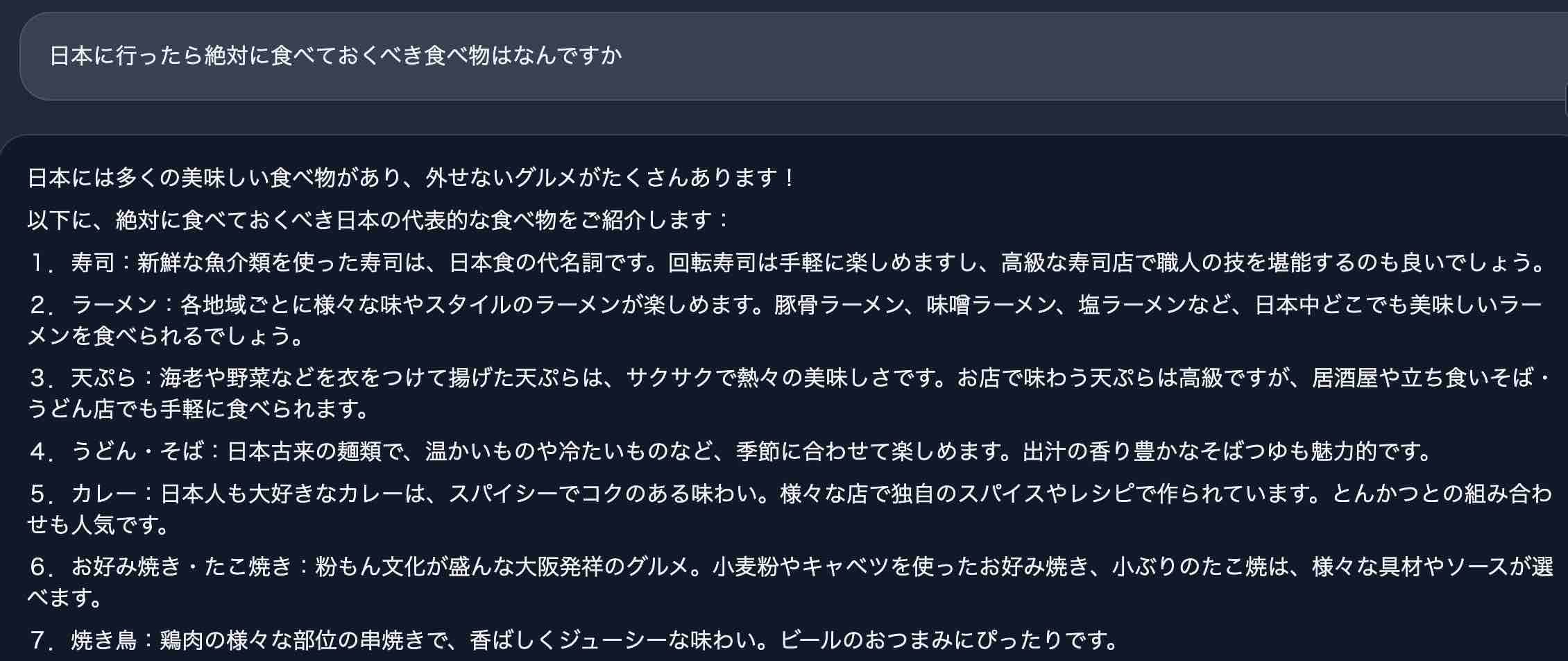
(画像:lmsys Chatbot Arenaから引用)
→ CohereForAI/c4ai-command-r-v01
⑦「ArrowPro-KUJIRA」:現役高校生が作った日本語特化のAIモデル

(画像:DataPilot/HuggingFaceより引用)
こちらは日本の現役高校生によってつくられたAIモデルです。
正確には、Mistral系の「NTQAI/chatntq-ja-7b-v1.0」というLLMをベースに日本語能力をアップさせたモデルとなっています。公開されたのは2024年5月で、パラメータ数が70億(7B)あります。
SNS上では、現役高校生が作ったAIモデルとして話題になりました。
また、モデルカードでは、ローカルAIの中でも屈指の日本語能力を有することが紹介されています。
赤いラインがArrowPro-7B-KUJIRAのスコアで、下にあるCommand-R-Plusの日本語能力とほぼ変わらないことが示唆されています。
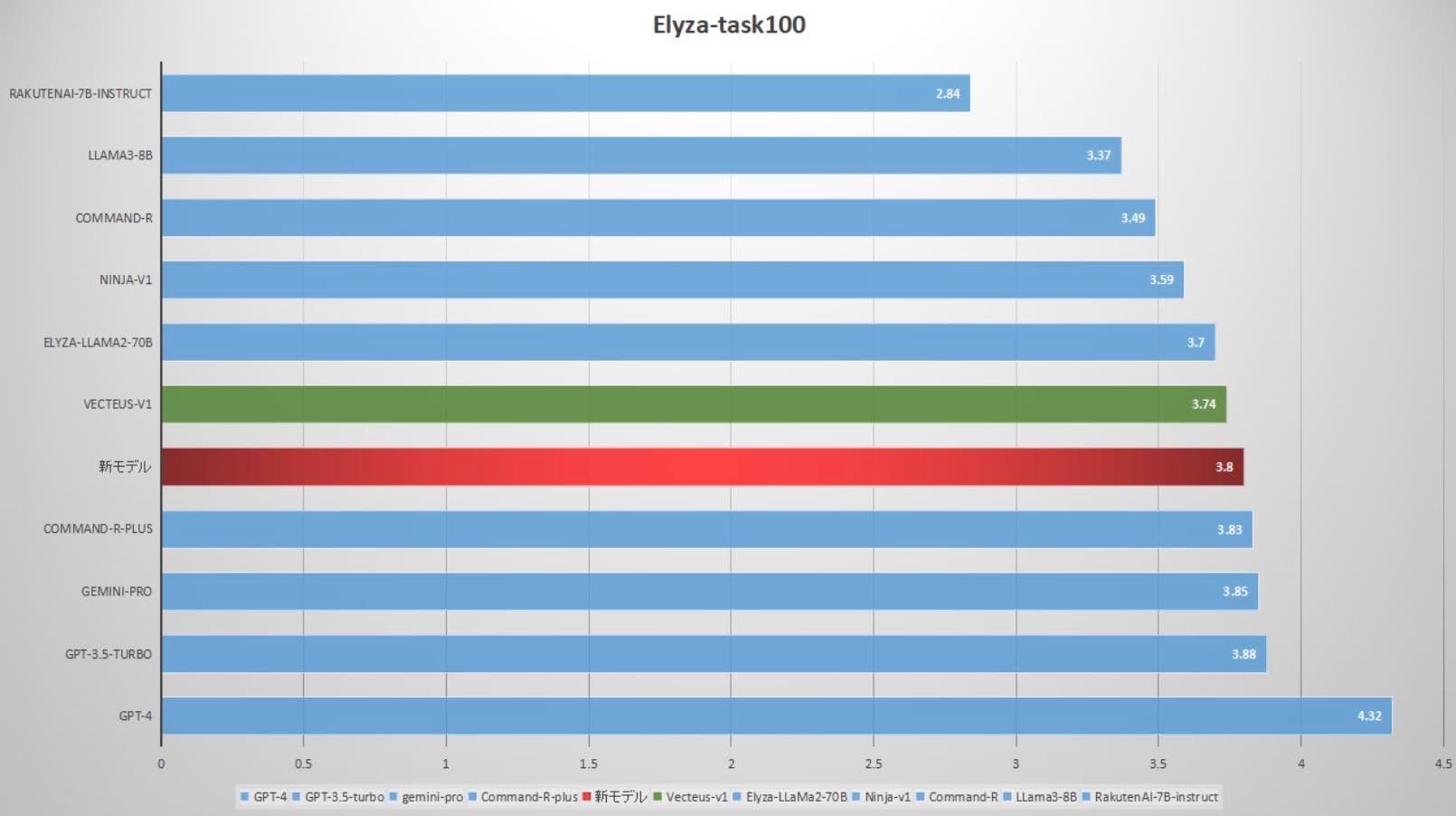
(画像:DataPilot/HuggingFaceより引用)
商用利用も可能なので、日本語のLLMを使いたい方はぜひ一度試してみることをおすすめします。
→ DataPilot/ArrowPro-7B-KUJIRA
⑧「RakutenAI-7B-Instruct」:楽天グループが開発したAIモデル

(画像:楽天グループ公式ホームページより引用)
楽天グループが公開しているオープンソースのLLMが「RakutenAI-7B-Instruct」です。2024年3月に公開され、高い日本語能力を持ったAIモデルとして注目を集めました。
パラメータ数は70億(7B)で、「Mistral-7B-v0.1」をベースに楽天のAIモデルはつくられたようです。
Apache 2.0のライセンスで公開されており、商用利用も可能です。
→ Rakuten/RakutenAI-7B-instruct
まとめ
いかがでしたでしょうか。実はこのようにまとめてみると、以外にも多くのオープンソース・ローカルのAIモデルが存在していることがわかります。
OpenAIやGoogleが出しているAIモデルは大衆向けに作られており、使いやすいかもしれません。
しかし、そのようなAIはインターネットが必要だったり、自分が望む日本語性能のアウトプットが出ないことも多々あります。
そんなときには、誰かがファインチューニングをしたローカルAIモデルを使ってみるのも良いかもしれませんね!
最後に、AI相談.comでは日本語でさまざまなAIキャラクターと会話ができるAIチャットボットをご用意しています。
ローカルモデルが気になる方は、AI相談.comのAIも触ってみてはいかがでしょうか。
参考文献 ・CohereForAI/c4ai-command-r-plus ・meta-llama/Meta-Llama-3-70B-Instruct ・Local-Novel-LLM-project/Vecteus-v1 ・elyza/ELYZA-japanese-Llama-2-7b-instruct ・Local-Novel-LLM-project/Ninja-v1 ・CohereForAI/c4ai-command-r-v01 ・meta-llama/Meta-Llama-3-8B-Instruct ・ Rakuten/RakutenAI-7B-instruct ・DataPilot/ArrowPro-7B-KUJIRA